I saw Casino Royale last night and was very impressed; impressed in many ways (especially the Treasury Rep. - anyone who has worked (with)in the British Civil Service knows how close to reality this sometimes seems). But that's not what stuck me.
I was amazed at my reaction to the sequence when Bond has broken into M's apartment to salvage some information from a SIM card he has salvaged. When he plugs it in and some technical wizardry provides him with the location of the last SMS message sent (a suitably exotic Bahamas), the app providing the information had to me the feel of a nice looking mashup combining yahoo maps and some backdoor-access telco data. I even wondered if I could go home and do the same for myself. It reminded me of the (again just ahead of reality) "I know this it's UNIX" bit in Jurassic Park.
The future (as they say) is now. Or maybe a few months away. I wonder if they're really mashing things up down there next to the Thames...
Sunday, December 24, 2006
Dim-neb-leh Annoying...
I did a windows cleanup last night in an effort to nudge my XP laptop into regaining some of the zip it has, of late, been lacking. When I then came to do a checkin to Subversion of some minor code changes I was confronted my error messages about missing .svn/tmp directories. Windows had helpfully removed evey one! I just had to go back through every directory, manually replacing them and then running svn cleanup. Dim-neb-leh annoying...
Friday, December 22, 2006
Netbeans VWP and My JPA1.0 Domain Model in Tomcat 5.5.17
I've been meaning to get this going for a while now and finally got round to it tonight. I have a domain model written using JPA1.0 annotations, Toplink for the implementation and MySQL for the RDBMS. I have it all masked off nicely behind a Session Facade and packaged into a simple jar. i want to call this from my Netbeans Visual Web Pack apps. Here's how I did it:
- Create the project making sure that the deployment target is the bundled Tomcat and not AppServer 9 (if you don't then you'll have to set up connection pools etc.)
- Add the domain model jar (which includes the persistence.xml file in the META-INF directory) to the new VWP project's libraries
- Also add the MySQL JDBC Driver and Toplink Essentials jars to the libraries
- Right click on the Application Bean in the Outline View and Add > Property and enter a name for your Session Facade variable and the name of the class
- Do this again for the field which you want to store your retreived info from the database (i.e. "username / String")
- In the constructor for the Application Bean initialise the Session Facade and then the storage field by calling the newly created facade to get the info you require from the database
- On Page1 Design View, drag a Static Text component onto the designer
- Switch to the Java view and in the prerender method set the text for the new component to be that which you just looked up and stored
- Hit deploy
- Et voila!
Thursday, December 21, 2006
Blog Tagged
[Think] I've been nominated![/Think]
[Do]Walk up to the stage. Time slows down. Sounds recede into the distance.[/Do]
[Think] I must be the exact opposite of the blogger type. Upon getting my first real link from a respectable source (Andy) via a game of blog tag and the click flow it may bring, I have no idea what to write (let alone who to tag). A voice is whipering "keep it simple. don't try to be clever. Definately don't get all puffed up about it". I'm not cut out for this kind of (web 2.0) world... Just read out the card...[/Think]
So the nominations for "Best Drunken Conversation Starter in a Starring Role (in my life) are...
And the winners are... [Do]Open envelope[/Do]
[Do]Walk up to the stage. Time slows down. Sounds recede into the distance.[/Do]
[Think] I must be the exact opposite of the blogger type. Upon getting my first real link from a respectable source (Andy) via a game of blog tag and the click flow it may bring, I have no idea what to write (let alone who to tag). A voice is whipering "keep it simple. don't try to be clever. Definately don't get all puffed up about it". I'm not cut out for this kind of (web 2.0) world... Just read out the card...[/Think]
So the nominations for "Best Drunken Conversation Starter in a Starring Role (in my life) are...
- My personal myth states that I decided I didn't want to be a vet when no a hot day's work experience a sheeps cancerous testicle the size of a large mango was cut open in front of me and a pea green soup like substance cascaded out, followed closely by a barrelling smell of decay. But...
- I have no sense of smell (guess that puts number one into perspective). However, when something is really bad I can taste it (so yes, to answer the standard follow up question,I can taste)
- I love Italian Horror Movies from the 60s and 70s. Most of all I love the zombie pics (think zombie flesh eaters, virgin amongst the living dead, the beyond, the house by the cemetary, dawn of the dead etc.) and the stalk and slash grindhouse stuff (like profondo rosso, suspiria and five dolls for an august moon) but the greatest film ever made by the greatest director that ever lived is the birds.
And the winners are... [Do]Open envelope[/Do]
- Stefanie Hollmichel at So Many Books
- if:book (because it deserves traffic)
- and finally David Cameron (more to see if he responds or not. [Think]I'll need to post a comment as I doubt he reads this avidly[/Think])
Friday, December 08, 2006
JavaUK Roadshow Linlithgow - Report
[I'd like to say I blogged this while I actually sat in the sessions; but that would be a lie. Good old pen and paper were the name of the day. I'd also like to point out that I used to work for Sun UK in the Java Software Team and as such am not the most impartial of witnesses]
Introduction
I attended the first (and hopefully not the last) JavaUK Road Show in Sun's Facility at Linlithgow, Scotland. The event was far better attended than I would have expected with nearly 40 delegates from both further education and industry. Spanning the whole day, the three major sessions covered "JavaCAPS, SOA and Web Services", "Moving Forward with Open Source" and "Free, Open and Innovative Tools for the Next Generation Web". Tying all these together was the concept of "the age of participation" - Sun's take on Web 2.0. I'll only cover the first session.
JavaCAPS, SOA and Web Services
This first session was tackled by Steve Elliot and provided an introduction to Sun's new Composite Application Platform Suite (aka CAPS) - in a nutshell their platform for SOA. While he (as will I) got onto product eventually it was very interesting to see how he framed Sun's take on the new flowering of internet technology buzzwords and concepts (generally lumped into "SOA" and "Web 2.0") in all their myriad forms and interpretations and used this to lead up to the pitch.
Just like in the dot.com boom of 6 years ago, it seems that Sun is again making a simple play to be the platform for this new web/network revolution. (Hands up who remembers "we're the dot in .com"? or the later "we make the net work"?) As a consequence, Steve started with an SOA "reality check" and explained what Jim Waldo (Sun employee and creator of Jini) has called the "Highlander Principle" - i.e. "there can be only one". A more apt title would be the "Highlander Fallacy" as his point is that this is a misconception. SOA, he explained, could be implemented using a variety of technologies, from Web Services (the current flavour of the month) to CORBA, RMI, Jini, DCOM, Raw Sockets etc. etc. The point being that there is a clear difference between architecture (the "A" in SOA) and implementation. He made it clear that Sun will continue to play in them all, and it is important not to get too pedantic about how it is done.
However, to narrow the field, he staked the Sun colours to the mast and said that their end was the enterprise end (where, for example, things like transactions are important). There was little attempt to define in detail or discuss the nature of the "S" - Service.
He then moved onto the alphabet soup that is "Web 2.0" and introduced a take which was all his own but very much in the Sun tradition of iconoclasm - "Dictionary Abuse" aka "All your words are belong to us". He went on to discuss the positioning of this on the Gartner Hype Curve before distilling it down to the concept of "The Age of Participation" summarised by a nice diagram of the world in "1.0" with a cloud with a large arrow coming down to the stick men (content access) below and a tiny one going back the way (content generation), complemented by the "2.0" could which has a even larger down arrow, but now also far larger up arrow.
Aside: Why the jump from SOA to Web 2.0? To be honest it made sense at the time but is a little stilted in the retelling. I think the best way to explain it is that Steve was trying to make things (and therefore by association Sun) cool and relate to the audience. Anyway, I digress...
The general 2.0 landscape laid out, Steve went on to link things up and discuss Sun's take on a (web) service, or more accurately how they can provide a platform for your service. The service was represented as a red blob (he stated he was keeping it simple). He introduced the analogy of the Victorians being the first real users of the SOA - they wanted tea, they wrang a bell and waited for the result. They didn't care how the tea got made orhow it got to them. It was all about the interface contract and end result. The same went for the blob. It's supposed to be opaque.
After this uncontroversial and functional depiction of a service, he then moved on to the meta or non functional features of the same. "How do I combine it with other services?" he asked. "What About Security and Identity?" and "What About QoS and SLAs?" he went on. He pointed out that not all services, or interactions with them will need to worry about these problems to the same extent, but did highlight that Governance (versioning) of services was key. He returned to this later.
He then listed the key principles which Sun feel an SOA should embody:
While we all know the list which I could reproduce here it is interesting to note the ones which were majored on. Namely the Liberty Alliance frameworks of ID-FF and ID-WSF, and most importantly the outcome of the Sun / Microsoft 10 year joint venture to provide greater .NET and Java interoperabilty. While you can find out more on the official sites, Steve was keen to stress that this was an engineering to engineering match up and something I tend to believe. (He showed some pics of Sun kit in the Redwood data centre.) It also seems to have been a meeting of equals (and a million miles from the recent announcements of the Novell / Microsoft love-fest) and was deifnately customer driven (they share a few blue chip customers in common who basically told them both to grow up). He then provided a quick overview of the output so far: Project Tango. This is provides greated interoperation between the Microsoft Windows Communications Foundation (WCF) messaging layer and Java EE Web Services. It was announced and demoed by Microsoft at JavaONE 2006 as WSIT ("Web Services Interoperability Technology"). So what does it provide specifically and how does it do it? Well, it adds richer protocol support, a richer security model and QoS support among other things but all without changing the JAX-WS (the latest incarnation of JAX-RPC) APIs. As a consequence you will be able to take advantage of these developments in your web services without having to change a single thing; it's all just extra configuration, not coding. Release is scheduled for 2007 on JavaSE 6 and JavaEE 5 with the Glassfish app server as the deployment platform. I didn't get a chance to ask if this would work on any other platforms.
Finally we moved onto a section entitled "The need for Business Process." Again the opening gambit was a classic Sun approach - via the standards. He explained that these days, to develop and expose a service is not enough. There is the need to compose and orchestrate a collection of these into something meaningful and useful. He mentioned WS-BPEL as being the current de-facto standard for describing long running and stateful business transactions which was "generally accepted by both the Java world and Microsoft." However, hand cranking BPEL is hard to do he said. It is an execution language only and not a modelling notation (i.e. that is visual). For this he said we needed BPMN whch layers on BPEL and will reach v.1.0 in 2007.
At this conclusion, finally a product appeared - Java CAPS Enterprise Designer. Its based on the Netbeans Platform (I think part of it has got into the free Enterprise Pack) and originated from the SeeBeyond acquisition. Its aimed at business analysts - all very drag and drop. To be honest, what we saw looked very nice and usable.
To tie this back to the main thread we concluded with a lightning tour of JBI. (aka JSR 208). Steve framed this by saying this was trying to do to SOA what Java EE did to the application server. This seemed sensible enough - all about how you provide a pluggable, core intergation system with seperate rules engines. He said that the orchestration engine will be BPEL, XSLT for the transformation engine and it'll first off interoperate with Web Services, MQ and FTP drops.
And that was it. To be honest I was pretty impressed. It was reassuring to see my alma mater pulling back from being everything to everyone and going back to what it knows best. There also seems to be a move to be "cool" again which is no bad thing. What with this, the open sourcing and the currently on tour Tech Days it seems they might just pull it off...
Introduction
I attended the first (and hopefully not the last) JavaUK Road Show in Sun's Facility at Linlithgow, Scotland. The event was far better attended than I would have expected with nearly 40 delegates from both further education and industry. Spanning the whole day, the three major sessions covered "JavaCAPS, SOA and Web Services", "Moving Forward with Open Source" and "Free, Open and Innovative Tools for the Next Generation Web". Tying all these together was the concept of "the age of participation" - Sun's take on Web 2.0. I'll only cover the first session.
JavaCAPS, SOA and Web Services
This first session was tackled by Steve Elliot and provided an introduction to Sun's new Composite Application Platform Suite (aka CAPS) - in a nutshell their platform for SOA. While he (as will I) got onto product eventually it was very interesting to see how he framed Sun's take on the new flowering of internet technology buzzwords and concepts (generally lumped into "SOA" and "Web 2.0") in all their myriad forms and interpretations and used this to lead up to the pitch.
Just like in the dot.com boom of 6 years ago, it seems that Sun is again making a simple play to be the platform for this new web/network revolution. (Hands up who remembers "we're the dot in .com"? or the later "we make the net work"?) As a consequence, Steve started with an SOA "reality check" and explained what Jim Waldo (Sun employee and creator of Jini) has called the "Highlander Principle" - i.e. "there can be only one". A more apt title would be the "Highlander Fallacy" as his point is that this is a misconception. SOA, he explained, could be implemented using a variety of technologies, from Web Services (the current flavour of the month) to CORBA, RMI, Jini, DCOM, Raw Sockets etc. etc. The point being that there is a clear difference between architecture (the "A" in SOA) and implementation. He made it clear that Sun will continue to play in them all, and it is important not to get too pedantic about how it is done.
However, to narrow the field, he staked the Sun colours to the mast and said that their end was the enterprise end (where, for example, things like transactions are important). There was little attempt to define in detail or discuss the nature of the "S" - Service.
He then moved onto the alphabet soup that is "Web 2.0" and introduced a take which was all his own but very much in the Sun tradition of iconoclasm - "Dictionary Abuse" aka "All your words are belong to us". He went on to discuss the positioning of this on the Gartner Hype Curve before distilling it down to the concept of "The Age of Participation" summarised by a nice diagram of the world in "1.0" with a cloud with a large arrow coming down to the stick men (content access) below and a tiny one going back the way (content generation), complemented by the "2.0" could which has a even larger down arrow, but now also far larger up arrow.
Aside: Why the jump from SOA to Web 2.0? To be honest it made sense at the time but is a little stilted in the retelling. I think the best way to explain it is that Steve was trying to make things (and therefore by association Sun) cool and relate to the audience. Anyway, I digress...
The general 2.0 landscape laid out, Steve went on to link things up and discuss Sun's take on a (web) service, or more accurately how they can provide a platform for your service. The service was represented as a red blob (he stated he was keeping it simple). He introduced the analogy of the Victorians being the first real users of the SOA - they wanted tea, they wrang a bell and waited for the result. They didn't care how the tea got made orhow it got to them. It was all about the interface contract and end result. The same went for the blob. It's supposed to be opaque.
After this uncontroversial and functional depiction of a service, he then moved on to the meta or non functional features of the same. "How do I combine it with other services?" he asked. "What About Security and Identity?" and "What About QoS and SLAs?" he went on. He pointed out that not all services, or interactions with them will need to worry about these problems to the same extent, but did highlight that Governance (versioning) of services was key. He returned to this later.
He then listed the key principles which Sun feel an SOA should embody:
- Secure
- Policy Driven
- Orchestrated
- Registered and Discoverable
- Standards Based and Driven
- Coarse Grained (services)
- Self Described
- (Mostly) Asynchronous
- Conversational
- Document Centric (as opposed to the old conception of them as XML-RPC focussed)
- Reliable
While we all know the list which I could reproduce here it is interesting to note the ones which were majored on. Namely the Liberty Alliance frameworks of ID-FF and ID-WSF, and most importantly the outcome of the Sun / Microsoft 10 year joint venture to provide greater .NET and Java interoperabilty. While you can find out more on the official sites, Steve was keen to stress that this was an engineering to engineering match up and something I tend to believe. (He showed some pics of Sun kit in the Redwood data centre.) It also seems to have been a meeting of equals (and a million miles from the recent announcements of the Novell / Microsoft love-fest) and was deifnately customer driven (they share a few blue chip customers in common who basically told them both to grow up). He then provided a quick overview of the output so far: Project Tango. This is provides greated interoperation between the Microsoft Windows Communications Foundation (WCF) messaging layer and Java EE Web Services. It was announced and demoed by Microsoft at JavaONE 2006 as WSIT ("Web Services Interoperability Technology"). So what does it provide specifically and how does it do it? Well, it adds richer protocol support, a richer security model and QoS support among other things but all without changing the JAX-WS (the latest incarnation of JAX-RPC) APIs. As a consequence you will be able to take advantage of these developments in your web services without having to change a single thing; it's all just extra configuration, not coding. Release is scheduled for 2007 on JavaSE 6 and JavaEE 5 with the Glassfish app server as the deployment platform. I didn't get a chance to ask if this would work on any other platforms.
Finally we moved onto a section entitled "The need for Business Process." Again the opening gambit was a classic Sun approach - via the standards. He explained that these days, to develop and expose a service is not enough. There is the need to compose and orchestrate a collection of these into something meaningful and useful. He mentioned WS-BPEL as being the current de-facto standard for describing long running and stateful business transactions which was "generally accepted by both the Java world and Microsoft." However, hand cranking BPEL is hard to do he said. It is an execution language only and not a modelling notation (i.e. that is visual). For this he said we needed BPMN whch layers on BPEL and will reach v.1.0 in 2007.
At this conclusion, finally a product appeared - Java CAPS Enterprise Designer. Its based on the Netbeans Platform (I think part of it has got into the free Enterprise Pack) and originated from the SeeBeyond acquisition. Its aimed at business analysts - all very drag and drop. To be honest, what we saw looked very nice and usable.
To tie this back to the main thread we concluded with a lightning tour of JBI. (aka JSR 208). Steve framed this by saying this was trying to do to SOA what Java EE did to the application server. This seemed sensible enough - all about how you provide a pluggable, core intergation system with seperate rules engines. He said that the orchestration engine will be BPEL, XSLT for the transformation engine and it'll first off interoperate with Web Services, MQ and FTP drops.
And that was it. To be honest I was pretty impressed. It was reassuring to see my alma mater pulling back from being everything to everyone and going back to what it knows best. There also seems to be a move to be "cool" again which is no bad thing. What with this, the open sourcing and the currently on tour Tech Days it seems they might just pull it off...
It's a Patriarchal Web (2.0)
My wife and I have finally got round to double barreling our names (long story but hers goes away entirely if she drops it, and there is a precedent for this kind of thing in my ancestry). I thought I'd go the whole hog, do it properly and change my email and all the places I've used it to sign up for things (that's a lot of places)
So I went to Google where I "live" online. I'd never really thought about having to do this before - not a thing guys do in a patriarchal society (not to mention a little wierd). I knew there'd be little chance of just changing the address I had (why not?) so I thought I could create a new address and then simply set up an auto forward or something. But to create a new address I had to "invite someone". To do this I had to create a temporary email address (good time to stake a claim on my new name at yahoo I rationalised), send them an invite from my existing gmail, accept, and then create a new gmail (or googlemail as it seems to be these days) account with my new, double barrelled name. Done. Fine. Quite a hassle, but fine.
OK, so now I want to have things "just work". It's optimistic I know but I take a lot of services from google (docs, calendar, blog, desktop, notebook, ...) and I want to be able to continue using them, but with my new name (/ email). After all, I didn't change it just to make my life more complicated.
So how do I do that? The answer seems to be "you can't". Everything I do I now realise is tied up to that same great email address-in-the-sky. My original, old one. It's damned annoying and seriously making me consider migrating to something a damn sight less monolithic. (I've already moved googledesktop to netvibes and am very pleased with the result). I mean it's "2.0" for crying-out-frikkin'-loud. What do I have to do? Wait until 3.0? I'm betting that if the web was created and run by women things would be a lot simpler (and maybe a little cuter too).
{Addendum 28/12/2006}
I managed to get it all done. As far as I know, I have now changed (or frigged) my online identity where ever it may lie to reflect my new identity. The Gmail thing definately sits in the "frig" category. I had to invite myself to GMail again, create a new address, and then set this in my old account as the primary address while setting a global forward and archive on the new account. Now as far as the outside world is concerned I have a new email. When in reality I've just "skinned" the old one. Still get access to all the archived mail and contacts. Sweet.
So I went to Google where I "live" online. I'd never really thought about having to do this before - not a thing guys do in a patriarchal society (not to mention a little wierd). I knew there'd be little chance of just changing the address I had (why not?) so I thought I could create a new address and then simply set up an auto forward or something. But to create a new address I had to "invite someone". To do this I had to create a temporary email address (good time to stake a claim on my new name at yahoo I rationalised), send them an invite from my existing gmail, accept, and then create a new gmail (or googlemail as it seems to be these days) account with my new, double barrelled name. Done. Fine. Quite a hassle, but fine.
OK, so now I want to have things "just work". It's optimistic I know but I take a lot of services from google (docs, calendar, blog, desktop, notebook, ...) and I want to be able to continue using them, but with my new name (/ email). After all, I didn't change it just to make my life more complicated.
So how do I do that? The answer seems to be "you can't". Everything I do I now realise is tied up to that same great email address-in-the-sky. My original, old one. It's damned annoying and seriously making me consider migrating to something a damn sight less monolithic. (I've already moved googledesktop to netvibes and am very pleased with the result). I mean it's "2.0" for crying-out-frikkin'-loud. What do I have to do? Wait until 3.0? I'm betting that if the web was created and run by women things would be a lot simpler (and maybe a little cuter too).
{Addendum 28/12/2006}
I managed to get it all done. As far as I know, I have now changed (or frigged) my online identity where ever it may lie to reflect my new identity. The Gmail thing definately sits in the "frig" category. I had to invite myself to GMail again, create a new address, and then set this in my old account as the primary address while setting a global forward and archive on the new account. Now as far as the outside world is concerned I have a new email. When in reality I've just "skinned" the old one. Still get access to all the archived mail and contacts. Sweet.
Friday, December 01, 2006
Maven 1.x and Google Web Toolkit
I'm fiddling with Google's Web Toolkit with an eye to using it to produce a new front end to a web app I've written. I'm a big fan of Maven and wanted to get my head round setting up a GWT project which runs as a maven project (and thenceforth within my IDE of choice - Netbeans). There is a maven plugin (actually there is one for Maven 1 and another for Maven 2) for GWT but the docs are a little sparse. I had a fiddle and soon got things going but I had a few problems along the way. Here's what I had to do (assuming you already have Maven 1.0.x installed):
- Download and install the current version of GWT for your platform. Instructions and binaries are here. Put the install directory in your path.
- Obtain the GWT plugin. This example currently only works with the 1.0 version. You need to get it from here and then after unzipping it cd into the expanded folder and run the command:
maven plugin:install-now - Then you need to get the GWT jar files (and .dll's) into your Maven repository. You'll find them in your GWT install directory. I copied them to a new
./.maven/repository/com.google.gwt/jars/folder. I had to placegwt-dev-windows.jar,gwt-servlet.jar,gwt-user.jar,swt-win32-3235.dllandgwt-ll.dllin there to get this all to work fine. NOTE: You could get the jars automatically too but I was behind a firewall and too lazy to set up Maven to get through it. - Now you can create your new GWT project. Create a directory (e.g. "
./sample/") to house your project somewhere sensible, change directory into it and run the following command:applicationCreator com.mydemo.gwt.client.SimpleDemo.This will create you a source code directory ("./src/") containing a hello world-style GWT application and two scripts for compiling and running your app. - Now we need to mavenise the directory structure. To do this change directory into
./src/and create three new directories calledjava,webappandtest. Then move the auto generatedcomdirectory and it's contents into the new./java/folder. NOTE: We won't use thewebappdirectory this time, but it's where we would put things like theweb.xmlfile if we had servlets as part of this application. - Finally we need to create the required maven config files as follows which all live in the project root directory ("
./sample/" in our case). NOTE: You'll need to edit the bits in red to suit your app and workstation:
project.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project>
<pomVersion>3</pomVersion>
<artifactId>mydemo</artifactId>
<groupId>com.mydemo.gwt</groupId>
<currentVersion>0.1</currentVersion>
<dependencies>
<dependency>
<groupId>com.google.gwt</groupId>
<artifactId>user</artifactId>
<version>1.0.20</version>
<jar>gwt-user.jar</jar>
<type>jar</type>
<properties>
<war.bundle>true</war.bundle>
</properties>
</dependency>
<dependency>
<groupId>com.google.gwt</groupId>
<artifactId>gwt-dev</artifactId>
<version>windows</version>
<type>jar</type>
</dependency>
</dependencies>
<name>GoogleWebToolkit and Maven Demo</name>
<package>com.mydemo.gwt</package>
<logo>/images/logo.gif</logo>
<inceptionYear>2005</inceptionYear>
<build>
<sourceDirectory>src/java</sourceDirectory>
<unitTestSourceDirectory>src/test</unitTestSourceDirectory>
<!-- Unit test classes -->
<unitTest>
<includes>
<include>**/*Test.java</include>
</includes>
</unitTest>
<resources>
<resource>
<directory>src/java</directory>
<includes>
<include>**/*</include>
</includes>
</resource>
</resources>
</build>
</project>
maven.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns:j="jelly:core">
<preGoal name="war:war">
<attainGoal name="gwt:compile"/>
</preGoal>
</project>
project.properties:
maven.war.src=src/webapp
google.webtoolkit.home=C:\Program Files\GoogleWebToolkit\gwt-windows-1.2.22
google.webtoolkit.runtarget=com.mydemo.gwt.SimpleDemo/SimpleDemo.html
google.webtoolkit.compiletarget=com.mydemo.gwt.SimpleDemo
google.webtoolkit.logLevel=SPAM
That's it, you're ready to go. Just run the maven target "gwt" and you'll see your app in the google debugger.
NOTE: This borrows heavily from an introduction to the maven GWT plugin created by Rober Cooper. His article on O'Reilly can be found here and the google code project for the plugin is here.
The Itinerant Techie's Kitbag
In my job I get sent to many different places to do many different things. However, wherever I go, there are some basic tools and resources that I need to have access to . Tools which, when I first started, were all located on my laptop, or even worse my home PC. Over the last year, and mainly by stealing things I see other people using, I've built up a browser based kit bag which allows me to free myself from my thick client and become as flexible as possible. The goodies are:
Oh and one more thing, if you can control what you install on your local systems and it's Firefox try Google Browser Synch. This means that all the Firefoxes you use can have the same remembered passwords, search history etc. Very clever.
If anyone has any other options, comments or things to add, please add a comment.
- Email - Simple really, but I used to use a thick (Thunderbird) client to my web mail. Recently web UI's (with the dawn of ubiquitous AJAX) have become very rich. Sign up for something like google mail or yahoo mail and learn the keyboard shortcuts. Oh, and keep your personal emails out of your work mailbox. Makes separation easier when you leave! If possible, add a widget to your shiny new web desktop (see below) so you can see what's in your inbox without having to have the page open. Oh and learn to use labels.
- Calendar - Have one, and one only. Again, I used to use my Outlook calendar. Then Google came along with one which integrated perfectly with my GMail. Get it to send you reminders. Same as the webmail, if possible add the widget to your new web desktop (see below) to see your calendar in miniature.
- Contacts - Again, put them in one place. Upload them all to your webmail service. GMail lets you upload CSV files which you can dump out of your thick mail client. Whenever a new contact comes along, make sure you add them.
- RSS Feeds - Get yourself a web desktop such as Google IG or Netvibes. Make it your home page. Create yourself some tabs to keep things organised and subscribe to all your RSS feeds in one place.
- To Do List - Using the web desktop mentioned above, find the To Do List Widget and add it to your front page.
- Post It's / Short Notes - Like when you have to take notes during a phone conversation - phone numbers and the like. Yet again, find the web desktop widget and add it.
- Bookmarks - Free your bookmarks from your browser! Move them all to something like del.icio.us. Now you can get at them from everywhere. And you're sharing them too. If you're interested in a freinds bookmarks, add the RSS feed for their del.icio.us page to your web desktop.
- Research Jottings - Start doing research on the web, using the web. Get a Google Notebook account and start sharing what you collect.
- Writing Documents and Spreadsheets - Stop doing them locally with Excel and Word and then sending out various copies and trying to merge in all the changes when you get them back. Get a Google Docs and Spreadsheets account and collaborate!
- Publish Information - If you have come across something you think others can make use of, publish it. Get yourself a blog for free and start letting others know what you know. Then incorporate their feedback.
- Instant Messaging / Web Conferencing - Collaborate across great distances for free with Google Talk or Skype. Get a headset to speak rather than type, web cams to see who you're talking too and shared drawing boards with uSeeToo. Store your Skype contacts centrally with Skype v.3.0.
- Podcasts - Subscribe to your favourite podcasts with iTunes. Charge up your iPod before you hit the road and keep up to date with all the news and tunes you need while away from your desk.
- Pics - Finally, it's nice to share your pics. There are loads of cool and free photo sharing tools out there such as Flickr!, Google Photos, or PhotoBucket. Get your freinds to join too so they can see the private pics you don't want the world to see. Maybe even get involved in some groups and see what others are doing.
- Disk Storage - This is something I don't yet use, and it's rumored that Google are working on a Google Disk. If you have any recommendations for a web disk, leave a comment and let me know.
Oh and one more thing, if you can control what you install on your local systems and it's Firefox try Google Browser Synch. This means that all the Firefoxes you use can have the same remembered passwords, search history etc. Very clever.
If anyone has any other options, comments or things to add, please add a comment.
Tuesday, October 17, 2006
JAXB, JIBX and Reverse Engineering XSD from my Java Object Model
I've got the requirement to output the contents of my object model in a readable fashion. What could be more readable than XML which led me to JAXB. The onyl problem is, with JAXB you start with the schema and go in the other direction. Step up to the mark JiXB. This allows you to go the other way and was very simple to get up and running.
- First step was download the bits and "install" (i.e. unzip) them (the "bits" I used were the core libs plus the utils. In my case "jibx_1_1.zip" and "jibxtools-beta2.zip"
- Copy the jibx-genbinding.jar and jibx-genschema.jar files from the tools zip file to the ./lib directory of your main JiBX "install"
- Open a command line and change directory to where your compiled classes are (NOTE: not the java source files as jibx uses introspection with the class files to do it's work. If they are in a package structure, make sure you are at the root of the package structure so that the cp declaration in the following command works. Otherwise you'll get a JiBXException about classes not being found)
- Auto-generate the binding file ("binding.xml") for your classes by running the following command:
- java -cp . -jar /home/myexampleuser/jibx/lib/jibx-genbinding.jar com.myexample.ClassA com.myexample.ClassB
- I had warnings at this stage about references to interfaces or abstract classes:
- Warning: reference to interface or abstract class java.util.Set requires mapped implementation
- I'd gone outwith the standard example on the website. Time to hit google... It turns out that out-of-the-box JiBX can handle some java.util.Collections fine like ArrayLists which my model also used but java.util.Sets (I'd used HashSet) were a little more troublesome. I needed to edit the newly created binding.xml file each time a Set-based relationship was found as follows:
- Original: <structure field="mySetOfAObjects" usage="optional">
</structure> - Updated: <collection field="mySetOfAObjects" factory="com.myexample.ObjectB.hashSetFactory">
<structure type="com.myexample.ObjectB" usage="optional"/>
</collection> - You'll have noticed that I seem to be calling a method "hashSetFactory()" on ClassB. This is the case, and it won't be there already. You need to add a static method to this class as follows:
- private static Set hashSetFactory() { return new HashSet();}
- You'll now be able to run the second command which will generate your xsd schema for you based on your new mapping binding.xml file:
- java -cp . -jar /home/myexampleuser/jibx/lib/jibx-genschema.jar binding.xml
- This will then generate you the xsd schema file you have been looking for all along.
Monday, August 21, 2006
Imagining Using the Portlet 2.0 (JSR 286) Early Draft 1 Spec Release
I've done some projects which have used JSR 168 Portlets in the past. When I saw that the first public released draft of the new spec was out I thought I'd take a look. Here's my imaginings of how things would have been if we'd used this spec instead...
Lets describe my imaginary app. (The standard kind of portler app I've worked on.) The setup is simple. There are three portlets. A “search” portlet and two content portlets: “films” and “actors”. You can use the search portlets single search field, coupled with a radio button selection of the search type (c.f. google) to search for either actors or films. The results of your search are displayed in the same portlet as a clickable list.
This is where the new "Portlet Co ordination" model comes in. The new spec (as I understand it) has added the concept of events which can be "thrown" (my terminology - almost in the same way as exceptions or events which are listened for in Swing apps is the impression that I get). These are then handled in an additional phase in the request action handling - rendering cycle which occurs after the relevant processAction() method is called, but before all the doView(), doEdit() etc. calls are made to generate the page fragments. As with wires, you can set attributes in the event (as standard types or even XML which is marshalled with JAXB - nice and flexible) which can then be picked up by those portlets which have elected (declaratively in the portlet.xml - again, nice and flexible) to react to specific
goings on which have happened (not only as a result of user interaction, but also emitted from the portal framework itself (c.f. pp. 75) The spec indicates that portlets can send what are termed "dynamic" events which are not declared in portlet.xml or, more usually static "declared" events. Finally I should note that a portlet can throw more than one event per processAction() call. Something which made things even more complicated with Websphere wires.
Clearly this is brilliant. How do we do it? Well, there's a new lifecycle interface for our portlet classes: javax.portlet.EventPortletInterface. This provides a new method which we must implement: processEvent(). To reinstate our old wired portlets, we need to take the Portlet classes we'd written, add the implementation of the interface, do some fairly hefty refactoring to move a lot of the code in many of the portlets processAction() methods to the new processEvent() method, declare our sending and receiving of events in the portlet.xml file and then deploy. Hooray! The complex WSDL for the exports and imports of data which WebSphere used for wiring is no longer required.
The final beauty of this new model is that the portal will now be happy to dynamically propagate any events as requested during operations. No more intervention is required after a successful deployment. (This is a vast improvement on WebSphere wiring jungle which would be remembered after subsequent deployments, but if you wanted to change a wire, you had to undeploy the entire portlet application and remove your portal pages again, then redeploy, put the pages back and then re wire using the admin GUI. If things still didn't work, then you'd have to undeploy, destroy and then repeat again. This wasted a lot of time.)
You should have guessed that I'm very happy that this has been added to the 2.0 spec. But while I do admit that it does seem a vast improvement on the way I have described above, I fear a few tricks have been missed in keeping this simple. Firstly, one of the few things I did like about the wiring method was that the wire effectively allowed you to call processAction() on one portlet, set a request parameter which would tell the wire to then call the processAction() on another portlet. It made sense to me and did not mean I had to understand (and debug) an increasingly complex class flow. Indeed, there could be multiple calls (as I outlined above where a click in a search result would get one portlet to display some detail and the other to reset itself) and each would follow the same route, initiated by the same original interaction from the user. The point I'm trying to make is that I'm not entirely convinced that there is a requirement for another portlet method, and its associated interface to implement. What is so vastly different between "actions" and "events" which means that they have to be handled separately?
Portlet development, even in the simplest sense is more complicated that it is with servlets - and rightly so, due to the slightly more complicated request - (action - render) - response cycle. But the aim should be to keep a sensible level of simplicity, otherwise potential developers will be driven away and the spec under used. Something JEE is only just recovering from. Consequently, it seems to me, that were the two new concepts of Portlet Co ordination and Shared Render Parameters (see below) to be linked and allow the proposed mechanism to call the processAction() methods rather than the additional processEvent() methods. The associated benefits of bookmarkable URLs (see below) could be leveraged and the present processing mechanism would be maintained. Code which was written for 1.0 could be simply updated (or in my case, little new would have to be done, we could just replace the wires with the new entries in portlet.xml to let on about who did the sending and who the receiving. Sorted.
Which brings me onto my second and final (and far shorter) area of feedback. I've already discussed what a nightmare getting the WebSphere wiring to work could be. It certainly seems vastly simpler with the "auto wiring" in the 2.0 spec, and the necessary xml configurations in portlet.xml are vastly simpler than the previous WSDL nightmare. But are the configurations necessary at all? Why do we still have to hack XML? - EJB3 showed us that annotations and sensible defaults can get us a great deal. I would also like to see the same sort of support in Portlet 2.0. Perhaps this is a way of implementing the (possibly necessary complexity) which led to the additional processEvent() step. As with EJB's, the Home, RemoteHome, and other interfaces are still there, it's just that the developer never needs to think about them, unless they choose to.
Before I close, I'd like to mention a few more quickies. Firstly, support for Java 5 - excellent - but why no support for JEE 1.5 rather than 1.4? Surely this would be an ideal to piggy back on what looks to be a storming, remarkably simplified and vastly more usable spec. The fact that the JPA can now be used outside an EJB container is a vast improvement. If portlets could then simply use this for the "M" in their MVC (we just used Hibernate and POJOs when we did our development) then everything done would be far more futureproof and allow portal implementations to run on Web Container only platforms.
Secondly, it is also very welcome to see the ability to share session state and render parameters. The possibililty of bookmarkable portlet URLs is an attractive one and will greatly increase usability and greatly simplify trying to handle the ever present threat of a user pressing the dreaded "back" button. The ability to share parameters outside the current portlet application is also a great improvement on a previously frustrating and seemingly arbitrary restriction.
All in all, I think this is a very promising looking 2.0 spec. I for one look forward to doing more portlet development in the future and coming up with even wilder ways to try and push the limits of what it can do.
NOTE: I haven't commented on the proposed AJAX or WSRP support. Both would be most welcome however and help the spec to be relevant to an even wider audience.
Lets describe my imaginary app. (The standard kind of portler app I've worked on.) The setup is simple. There are three portlets. A “search” portlet and two content portlets: “films” and “actors”. You can use the search portlets single search field, coupled with a radio button selection of the search type (c.f. google) to search for either actors or films. The results of your search are displayed in the same portlet as a clickable list.
This is where the new "Portlet Co ordination" model comes in. The new spec (as I understand it) has added the concept of events which can be "thrown" (my terminology - almost in the same way as exceptions or events which are listened for in Swing apps is the impression that I get). These are then handled in an additional phase in the request action handling - rendering cycle which occurs after the relevant processAction() method is called, but before all the doView(), doEdit() etc. calls are made to generate the page fragments. As with wires, you can set attributes in the event (as standard types or even XML which is marshalled with JAXB - nice and flexible) which can then be picked up by those portlets which have elected (declaratively in the portlet.xml - again, nice and flexible) to react to specific
goings on which have happened (not only as a result of user interaction, but also emitted from the portal framework itself (c.f. pp. 75) The spec indicates that portlets can send what are termed "dynamic" events which are not declared in portlet.xml or, more usually static "declared" events. Finally I should note that a portlet can throw more than one event per processAction() call. Something which made things even more complicated with Websphere wires.
Clearly this is brilliant. How do we do it? Well, there's a new lifecycle interface for our portlet classes: javax.portlet.EventPortletInterface. This provides a new method which we must implement: processEvent(). To reinstate our old wired portlets, we need to take the Portlet classes we'd written, add the implementation of the interface, do some fairly hefty refactoring to move a lot of the code in many of the portlets processAction() methods to the new processEvent() method, declare our sending and receiving of events in the portlet.xml file and then deploy. Hooray! The complex WSDL for the exports and imports of data which WebSphere used for wiring is no longer required.
The final beauty of this new model is that the portal will now be happy to dynamically propagate any events as requested during operations. No more intervention is required after a successful deployment. (This is a vast improvement on WebSphere wiring jungle which would be remembered after subsequent deployments, but if you wanted to change a wire, you had to undeploy the entire portlet application and remove your portal pages again, then redeploy, put the pages back and then re wire using the admin GUI. If things still didn't work, then you'd have to undeploy, destroy and then repeat again. This wasted a lot of time.)
You should have guessed that I'm very happy that this has been added to the 2.0 spec. But while I do admit that it does seem a vast improvement on the way I have described above, I fear a few tricks have been missed in keeping this simple. Firstly, one of the few things I did like about the wiring method was that the wire effectively allowed you to call processAction() on one portlet, set a request parameter which would tell the wire to then call the processAction() on another portlet. It made sense to me and did not mean I had to understand (and debug) an increasingly complex class flow. Indeed, there could be multiple calls (as I outlined above where a click in a search result would get one portlet to display some detail and the other to reset itself) and each would follow the same route, initiated by the same original interaction from the user. The point I'm trying to make is that I'm not entirely convinced that there is a requirement for another portlet method, and its associated interface to implement. What is so vastly different between "actions" and "events" which means that they have to be handled separately?
Portlet development, even in the simplest sense is more complicated that it is with servlets - and rightly so, due to the slightly more complicated request - (action - render) - response cycle. But the aim should be to keep a sensible level of simplicity, otherwise potential developers will be driven away and the spec under used. Something JEE is only just recovering from. Consequently, it seems to me, that were the two new concepts of Portlet Co ordination and Shared Render Parameters (see below) to be linked and allow the proposed mechanism to call the processAction() methods rather than the additional processEvent() methods. The associated benefits of bookmarkable URLs (see below) could be leveraged and the present processing mechanism would be maintained. Code which was written for 1.0 could be simply updated (or in my case, little new would have to be done, we could just replace the wires with the new entries in portlet.xml to let on about who did the sending and who the receiving. Sorted.
Which brings me onto my second and final (and far shorter) area of feedback. I've already discussed what a nightmare getting the WebSphere wiring to work could be. It certainly seems vastly simpler with the "auto wiring" in the 2.0 spec, and the necessary xml configurations in portlet.xml are vastly simpler than the previous WSDL nightmare. But are the configurations necessary at all? Why do we still have to hack XML? - EJB3 showed us that annotations and sensible defaults can get us a great deal. I would also like to see the same sort of support in Portlet 2.0. Perhaps this is a way of implementing the (possibly necessary complexity) which led to the additional processEvent() step. As with EJB's, the Home, RemoteHome, and other interfaces are still there, it's just that the developer never needs to think about them, unless they choose to.
Before I close, I'd like to mention a few more quickies. Firstly, support for Java 5 - excellent - but why no support for JEE 1.5 rather than 1.4? Surely this would be an ideal to piggy back on what looks to be a storming, remarkably simplified and vastly more usable spec. The fact that the JPA can now be used outside an EJB container is a vast improvement. If portlets could then simply use this for the "M" in their MVC (we just used Hibernate and POJOs when we did our development) then everything done would be far more futureproof and allow portal implementations to run on Web Container only platforms.
Secondly, it is also very welcome to see the ability to share session state and render parameters. The possibililty of bookmarkable portlet URLs is an attractive one and will greatly increase usability and greatly simplify trying to handle the ever present threat of a user pressing the dreaded "back" button. The ability to share parameters outside the current portlet application is also a great improvement on a previously frustrating and seemingly arbitrary restriction.
All in all, I think this is a very promising looking 2.0 spec. I for one look forward to doing more portlet development in the future and coming up with even wilder ways to try and push the limits of what it can do.
NOTE: I haven't commented on the proposed AJAX or WSRP support. Both would be most welcome however and help the spec to be relevant to an even wider audience.
Wednesday, July 26, 2006
Tuesday, July 11, 2006
EJB 3.0: One Model Inside and Out (Pt. 2) - The POJO Model Itself – Annotations and Relationships
Please note, this blog entry is based heavily on many other things out there on the web at the moment, most particularly this tutorial on netbeans.org. I've taken this liberty, as I thought I needed to provide a firm bedrock upon which to build my later entries in this series where I do go into uncharted territory. If I have infringed any copyright, please do tell me and I will take appropriate action.
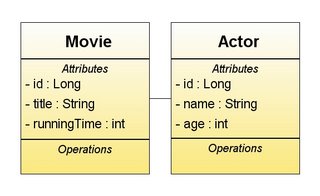
I hate databases. We don't get on. They don't respect me, and as a result I don't respect them. Therefore I always like to start my OO apps. by encapsulating the domain model in a class model. For the Loads-A-Movies project mine was very simple:
That's all for this entry. There is far more information on the possibilities of EJB 3.0 persistence which I haven't gone into. The best sources for more information I have found are as follows:
I hate databases. We don't get on. They don't respect me, and as a result I don't respect them. Therefore I always like to start my OO apps. by encapsulating the domain model in a class model. For the Loads-A-Movies project mine was very simple:
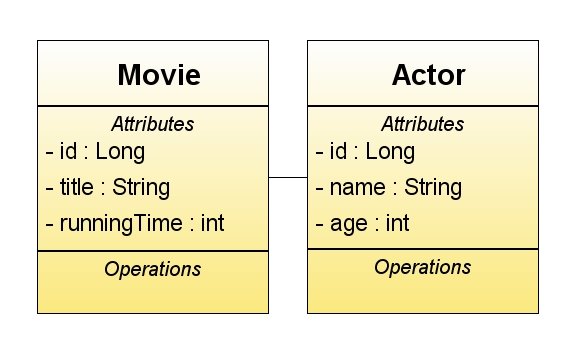
If it looks simple, it's supposed to. Lets create the classes.
Creating the Movie Entity Class
This will represent the table “MOVIE” in the database. We first need to generate a simple, serializable java POJO class with the attributes shown above encapsulated as appropriate (you can do this automatically with your chosen GUI). This now needs to be annotated to let the compiler know how to treat it. (Note: This requires JDK annotation support which you'll get if you use Java 5)
...
public class Movie implents Serializable {
private Long id;
private String title;
private int runningTime;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
...
First up we need to let on this is an Entity Class. We do this simply by using the “@Entity” annotation before the “public class Movie implements Serializable” line. The compiler is now clever enough to know that, unless told otherwise, the attributes on this class will be represented as columns in our table. That's how EJB 3.0 works. It assumes the default, unless you tell it different. Very handy.
...
import javax.persistence.Entity;
...
@Entity
public class Movie implents Serializable {
...
The observant amongst you will realise that we most likely need a primary key. Correct, each entity class must have a primary key. When you create the entity class, we must add an @Id annotation to the “id” attribute to declare we plan to use it as the primary key. We also add the @Generated... annotation to specify the key generation strategy for the primary Id. In our case:
...
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
...
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
...
Finally for Movie, there is the interesting case of the relationship with the Actor Entity class. Firstly we need to add the collection attribute, “Collection
import javax.persistence.OneToMany;
...
@OneToMany(mappedBy="movie")
private Collectionactors;
...
And that's the Movie Entity class coded. We now need to do the same for the Actors. As before, create a POJO class (ensuring you “implement Serializable”) with the required attributes encapsulated. This will represent the "ACTOR" table in the database. Again define it as an Entity with the @Entity annotation and mark the “id” attribute as the primary key and set it to
be auto generated with the @Id and @Generated tags.
Again we need to add the new attribute. in this case it's the Actior nowing about the film he has appeared in:
private Movie movie;
Again, encapsulate this attribute. Finally we need to add the annotation to let on that this is the reverse direction of the previous relationship. We do this by putting the following annotation above the new movie declaration:
import javax.persistence.ManyToOne;
...
@ManyToOne
private Movie movie;
Note: You'll have noticed that you require imports for these annotations. These are contained in the “javaee.jar” package which I needed to declare as a dependency in my maven project.xml file. I found the one I used in my GlassFish server's /lib directory. If you're doing it differently maybe your IDE has suggested one for you.
That's all for this entry. There is far more information on the possibilities of EJB 3.0 persistence which I haven't gone into. The best sources for more information I have found are as follows:
- Java Persistence in the Java EE Platform - tutorial at netbeans.org
- Standardizing Java Persistence with the EJB3 Java Persistence API - Article at OnJava.com
- The Java Persistence API - A Simpler Programming Model for Entity Persistence - Article at java.sun.com
EJB 3.0 - One Model Inside and Outside the Container (Pt. 1)
I'm writing a suite of (i.e. two) applications which share an object model. I'm a trained J2EE architect and consequently I love the idea of maximum code reuse. I'm also lazy. In the following series of blog entries I'm going to explain how I managed to achieve this using Java 5, EJB 3.0 (including persistence) and Maven.
First up, lets have a quick overview of what I'm trying to achieve. The plan is to create a website to store information about my film collection. I want to be able to do all kinds of fancy things but really it's an excuse to fiddle around with Java 5, generics, annotations, JSF, EJB 3.0 and Maven. I have a cunning plan however. I love the idea of the Flickr uploader but I want to take it further. What if I could have a local, thick Swing app. which I could keep in sync. with my web app. and use to upload and maintain info on my public website? It could use the same model code... That would be cool. It would also let me fiddle with the Matisse GUI builder, Derby and most importantly the Napkin look and feel...
So how am I going to approach this? Well, the plan is to have three separate maven projects, with all the common stuff factored out into a code-less master project (I won't go into this any further, that's a separate blog entry). The first is to be the model project; “loadsamovies-model” which we will discuss in the next blog, the second the web presentation layer; “loadsamovies-presentation” which I don't plan to go into as the techs and methods is covered in great detail elsewhere. The last is the uploader Swing app; “loadsamovies-thickclient”
See the next entry for how I coded up the model.
First up, lets have a quick overview of what I'm trying to achieve. The plan is to create a website to store information about my film collection. I want to be able to do all kinds of fancy things but really it's an excuse to fiddle around with Java 5, generics, annotations, JSF, EJB 3.0 and Maven. I have a cunning plan however. I love the idea of the Flickr uploader but I want to take it further. What if I could have a local, thick Swing app. which I could keep in sync. with my web app. and use to upload and maintain info on my public website? It could use the same model code... That would be cool. It would also let me fiddle with the Matisse GUI builder, Derby and most importantly the Napkin look and feel...
So how am I going to approach this? Well, the plan is to have three separate maven projects, with all the common stuff factored out into a code-less master project (I won't go into this any further, that's a separate blog entry). The first is to be the model project; “loadsamovies-model” which we will discuss in the next blog, the second the web presentation layer; “loadsamovies-presentation” which I don't plan to go into as the techs and methods is covered in great detail elsewhere. The last is the uploader Swing app; “loadsamovies-thickclient”
See the next entry for how I coded up the model.
Sunday, July 09, 2006
Booting Apache Derby ("JavaDB") with your Java App's Startup
If you're embedding the Derby RDBMS with your java desktop application and want it to start when you start your app, you need to make the following call somewhere in your code (i.e. in main() or an init() method):
It's important to notice (as I didn't to begin with) that you need the local version of the URL as you are doing this using the embedded driver. If you use the URL version you'll get a "java.sql.SQLException: No suitable driver" error.
You'll also notice that this creates the database with the name provided in a directory with the name provided, (e.g. "sample"). This directory will be in the same place as the main class you are running.
One final thing, this is dead easy to use with EJB 3.0 too. All you need to do is set up your persistence manager to run outside a container and as soon as you have started your embedded database, you can connect to it with something like TopLink. Beautiful....
// Start the Derby Database
try {
Class.forName("org.apache.derby.jdbc.EmbeddedDriver")
.newInstance();
} catch (ClassNotFoundException ex) {
ex.printStackTrace();
} catch (InstantiationException ex) {
ex.printStackTrace();
} catch (IllegalAccessException ex) {
ex.printStackTrace();
}
// Set the connection to the database
Connection conn = null;
try {
conn = DriverManager
.getConnection("jdbc:derby:sample;create=true");
} catch (SQLException ex) {
ex.printStackTrace();
}
It's important to notice (as I didn't to begin with) that you need the local version of the URL as you are doing this using the embedded driver. If you use the URL version you'll get a "java.sql.SQLException: No suitable driver" error.
You'll also notice that this creates the database with the name provided in a directory with the name provided, (e.g. "sample"). This directory will be in the same place as the main class you are running.
One final thing, this is dead easy to use with EJB 3.0 too. All you need to do is set up your persistence manager to run outside a container and as soon as you have started your embedded database, you can connect to it with something like TopLink. Beautiful....
Saturday, July 08, 2006
Ubuntu Superusers
I came to Ubuntu (Dapper Drake) from Solaris. I thought I'd be able to log in as the root user or su from the command line to my heart's content. It's not that simple. By default you can't log in or su to the root user as I expected. To perform admin tasks as a non root user you need to use the sudo command (this was in fact running for me withjout my knowledge as I ran the various admin tasks to set things up after install. For info on the sudo command, look at the Dapper documentation wiki.
Thursday, June 08, 2006
Creating an EJBQL query using a constructor expression in the SELECT clause
I'd read you could construct an entity summary dto direct from an EJBQL query. After a little fiddling I got it to work as follows:
The DTO in this case was a very simple java bean. I didn't need to declare it in persistence.xml. I did have to use the fully qualified classname however otherwise Toplink (in my case) couldn't find the constructor.
public ListlistEntitySummaries() {
String query
= "select new com.myapp.model.dto.MyEntitySummaryDTO(e.id, e.title) from MyEntity e";
return (List) em.createQuery(query).getResultList();
}
The DTO in this case was a very simple java bean. I didn't need to declare it in persistence.xml. I did have to use the fully qualified classname however otherwise Toplink (in my case) couldn't find the constructor.
Monday, June 05, 2006
EJB3: Listing the Complete Contents of a Table
It took me a while to work this out. Here is is for posterity:
String queryString = "SELECT r FROM Recipe r WHERE r.id > 0";
Query myQuery = em.createQuery(queryString);
List result = myQuery.getResultList();
String queryString = "SELECT r FROM Recipe r WHERE r.id > 0";
Query myQuery = em.createQuery(queryString);
List result = myQuery.getResultList();
Note to Self: Windows Pathnames in Java
This gets me every time. I had to specify a jvm option in a maven properties file. It took ages, due to spaces in the path name. This worked:
Hopefully I don't forget again...
maven.junit.jvmargs=-javaagent:C:\\Docume~1\\anlaw\\.maven\\repository\\javax.persistence\\jars\\toplink-essentials-agent.jar
Hopefully I don't forget again...
Maven 1.0.2: Adding a resource to a jar
Want to add a resource such as an xml config file to your generated jar in Maven 1.0.2?
<resources>
<resource>
<directory>${basedir}/resources</directory>
<includes>
<include>**/[file to include.xml]</include>
</includes>
</resource>
</resources>
</build>
Create your jar, and et voila!
- Create a directory called ./resources in the base directory fo your project and place what you want to include in it (if you want to place it in a specific directory in the jar, such as META-INF, echo the dir strcuture you want in the jar)
- Add the following to your POM:
<resources>
<resource>
<directory>${basedir}/resources</directory>
<includes>
<include>**/[file to include.xml]</include>
</includes>
</resource>
</resources>
</build>
Create your jar, and et voila!
Thursday, June 01, 2006
Agile Development Ramblings: Part IV
The Documentation and Handover
The Documentation and Handover
Up to this point, we had been very successful. As far as the AU's were concerned, we had done a great job. They were all happy to sign off the finished product. However we had not built the final, deployable product. While not strictly speaking a true prototype (the vast majority of the front end code was planned to be kept rather than thrown away) everything behind our Session Facade was to be re engineered. This was to accommodate a wider and separately architected Strategic Portal Framework based on Websphere Portal and an SOA based Model / Persistence store.
In addition, this further development work was not to be conducted in-house and was instead to be handed to a development partner with little Agile experience. Further compounding this was the fact that further development was not scheduled to begin immediately. The original plan had been for us to verbally hand over as much information as possible. This was now impossible. Instead, we had one week to write it all down. To be fair, an awful lot already was. Indeed a great deal was already encoded in things like Maven. What we didn't have was anything about the architecture. Nothing up to date or accurate anyway.
The Agile Architect?
The point of Agile programming and development, I have learned, is that “the Code is the Blueprint”. Roughly translated, this means that everything you need to know about the resulting application is in the code; be this the code itself, the comments, the javadoc, or all the supporting (usually auto generated) xml and database schemas and properties files. This is all well and good, but to be able to understand it, you need to know Java and SQL. You also need a lot of spare time and better hope the developers write legible code.
This wasn't what the development partner was expecting, and so we had to go about reverse engineering things such as Logical Data Models, UML Diagrams, textual descriptions of the Architecture etc. This wasn't very Agile. We had been lucky in that we hadn't had a requirement to continuously produce these artifacts throughout the process. It would have hampered our progress considerably, always updating them and making sure they were accurate. However, it was clear why each and every one of them had been requested.
There is a current trend in the Agile world against the “Architect” and I agree that it is a grossly overloaded term. However, not everyone can, or should have to read code to see how something works. There is a requirement, even a need for there to be an intermediary between the Business Analysts and the Developers. There is a need for the production of logical and conceptual models which avoid implementation detail but provide enough data to inform strategic discussions as well as the nuts and bolts of building the thing.
A major benefit of Agile is that developers are plugged into the eventual users of their system, rather than being obscured from them by the analysts, architecture and architects. However, the current model of an architect is the “Big Up Front Design” / “Big Requirements Up Front Requirements” type of person which Agile has shown to be lacking. The old “develop to a paper plan and an interface” model Developer is changing, and I believe that Architects need to do the same; perhaps adopting a hybrid role like that which I played on this project will emerge – what I call the “Side On” approach (as opposed to the traditional “Top Down” or “Bottom Up” approaches). Then everyone has a relationship with the users. Perhaps not. Time will tell.
Either way, this isn't the place to go into this in depth, but it's something which I believe you'll see more and more debate about in the months and years to come. I personally plan to learn the lessons of Agile and try to apply them to my other kinds of engagements from now on. So what are the big lessons I've learned over the last 14 weeks?
Lessons Learned
- Remember the “10 Commandments” [link]
- While this project benefited from a number of favorable conditions (small and discrete and defined scope) I firmly believe that Agile methodologies can cope with far larger projects and less well defined scope and requirements. They are designed to manage the risks this brings while embracing the increased flexibility.
- The quality was evident – we never had a major bug appear during demos to users. this instilled confidence in the Ambassador Users and it also helped the process in that the users could "play" with the system and understand the evolving requirements.
- Have a demo box permanently available. This was requested a lot by our AU's but it was too difficult to achieve. But would have helped to get more users have hands on earlier on in the process, and help with wider user group buy in / adoption.
- Don't however waste time setting up the demo box again and again – automate it (with Cruise Control and Maven)
- One important aspect of an iterative process is that it can be continually reviewed throughout the project lifecycle. The team took advantage of this, resulting in an improved format for the workshops and new implementing reporting and testing procedures.
- You must be disciplined
· Think about what you are doing and ask “Does it add value? Does it help towards delivery?”
· We didn't always follow our own standards. Sometimes it might have been better to enforce things with Subversion, Maven, PMD and Checkstyle.
- It is essential that different user groups respect and understand the prioritisation objectives of others. This was certainly the case on this project.
- It was also important that the Ambassador Users had the appropriate skills and experience to drive the project requirements forward and they were empowered to make decisions pertaining to the prioritisation and implementation of features.
- It was of benefit to the AU's themselves to be round the same table though they come from different backgrounds and have different requirements. They gain a shared understanding through their participation
· What did the close developer / user bond require?:
(a) Developer communication skills – of highest importance – else you build lots, but you build the wrong thing
(b) Delivered code must be understandable to those who will interact with it
in the future
(c) Every feature built must be deployable - Even if the end result is not deployable (i.e. ours had no security so wouldn't go live)
(d) Buy in and understanding from all – Leads to a shared sense of responsibility
(e) Honesty from all – If you don't understand, say so; If you don't like, say so; ...
· What did the close developer / user bond result in?:
(f) It positively affected developers understanding of what will happen to their product once work is complete
(g) The developer sees who will use their system, rather than imagining them.
(h) The developer becomes aware of the change management, training and update issues after their work is complete
(i) Everyone is empowered
(j) Greater visibility for all participants
- I, and others were amazed how much could be achieved in such a short period of time.
- The lack of documentation in Agile projects makes people used to traditional approaches feel uncomfortable.
- Communicate, communicate, communicate
- You are not your code. Take pride in what you do, but let go once you check in.
- Keep it simple. If it gets complicated, refactor.
- Naming is very important. Agree on a strategy early on, then stick to it. If possible, enforce it with Checkstyle
- Identify and stick to standards and best practices throughout
- Tooling is important. If there's a plugin or a Wizard, you can save time.
· Frameworks save time, but add complexity. We didn't use one for MVC as things for us were simple.
- Only use tools and frameworks as and when required
· But make sure you don't make them harder to adopt in the future if you decide to not use then from the get-go
Agile Development Ramblings: Part III
The Development
The Development
So far I've said a lot about the process, but nothing about the actual development. No prizes for guessing that this was different to my previous experiences too.
Development Environment Setup
We had to do this ourselves, so no time was wasted. From day one we had a server and by day two we were building both it and our development desktop systems with the software we required. We had few NFR's in this department apart from the requirement to use Websphere Portal and JSR168 Portlets. We also had to use Rational Application Developer 6.0 as our development IDE, and make sure our portlets were accessible and internationalisable. I do not think it would have been a problem had we had more NFR's, as long as the required media were made available to us. The fact we did not have to rely on anyone else; or an internal process was a boon.
We were left to our own devices. With access to the internet and an IBM Partner Web account we got to work. The systems we were given had nothing installed on them aside from Windows. We quickly decided to use Maven as the build and project management environment, MySQL and Hibernate for persistence, Subversion for configuration management, and CruiseControl for continuous integration. Each of the tools we used was picked after discussion between myself and the other developer. Installation tasks were split down the middle, with Notepad “what I did” notes being created and shared as we went.
This time didn't go entirely smoothly. RAD took ages to deploy and upgrade and we gave up getting the Portal Unit Test Environments (UTE's) to work on our desktops. (This turned out to be due to a known bug.) This however introduced me to the highly pragmatic approach to development any agile approach necessitates. You've got a problem; you have a think about what the relative costs and benefits of something are; if it's worth it, and doesn't endanger the delivery of features, go for it; if not, don't. If this is a real problem, you can flag it to the rest of the team and note it in the “Obstacles” section in the Sprint Plan. After such analysis, none of our problems were significant enough to reach the plan. In the case of the UTE's we decided that due to the small size of the team, we could use the shared server running a single instance of Portal and a single database for deployment and testing. It would require us to communicate constantly to make sure we didn't tread on each others toes, but this actually helped in 99% of situations. We never ended up developing in a vacuum.
All this meant that by the end of the first week we had an environment we were happy with, which we understood and would support our chosen approach.
The Coding
Again we took the agile approach. The aim was always to be developing and delivering as much as possible. At the outset, we set few constraints on ourselves. What we did have covered coding style, SVN commit protocol, Unit Testing coverage and approach and division of labour. Later on, as required, we bolted on Checkstyle and PMD, JWebUnit and JSTL. A unit testing protocol was forced on us as the default Maven target to produce our model jar file (“jar:deploy”) required that all unit tests passed. This proved invaluable and frequently caught problems in their infancy.
Build and Project management was light too. Maven was a boon in this respect. We only had to write thirteen lines of bespoke script in one project (to copy our Hibernate hbm.xml files from one place to another) and twenty in another (to call XMLAccess to deploy our portlet war to the Server). Everything else was already there for us, provided by the Maven plugins.
Maven also supported the project management, providing an automatically generated project website (via the “site” target) which allowed us to publish our how-tos to the wider team as we produced them. At the end of the development cycle, this proved an invaluable central repository for everything we produced over the proceeding thirteen weeks.
It is worth noting some of the practices I became familiar with during the development phase. The most fundamental was the aim to “write it once”, better still use a plugin or generate it. A good example follows:
Though we used MySQL as our data store, we never had to write any SQL. We didn't even have to write the hibernate mapping files. Instead, we generated them with XDoclet tags. To get from the tags to the schema, we called pre-existing Maven targets (“xdoclet:hibernatedoclet" and “hibernate:schema-export”) to generate our schema. This not only meant we got things going more quickly, and had fewer bugs (less code), but also we had automated what would otherwise have been very commonly executed task. Most importantly, these repetitive steps were taken out of our hands so there was less chance of losing valuable development time debugging what may turn out to be user error.
As with the setup phase I also had to focus 100% on delivery. I constantly asked myself “what is the value of what I am doing? Is it meeting the delivery goals? Is there something of more value I could be doing? Is there a better way to do what I am doing? Is it over redundant complicated / over engineered?”
All in all, we completed our six Sprints having delivered all the “Must Have” features and a large chunk of the “Should Have”s and “Could Have”s. We then moved into the final week for User Acceptance Testing and handover to the development partner. It was then that in my opinion our use of the Agile process showed some weaknesses.
The UAT
This however went very well. Every single AU completed all the tests, signing off every single point of functionality. As the process was agile, we were able to fix every minor bug which the testing highlighted before the final UAT, and also implement some minor “Could Have”s (such as clear buttons on search forms, default selections on drop downs, alphabetization of lists, etc.)
This was possible because we, as developers, had by this time formed a solid relationship with all our users. By seeing them really using the system in anger (we told them there were prizes for breaking it) we gained a further depth of understanding of the real usability of our system. This is something I personally have rarely experienced and it was enlightening. The project team agreed that if we had known the power of this earlier, we would have got the users to have one to one hands on sessions more frequently, earlier in the process. The benefits of this to the final product are hard to pin down quantitatively, but self evident in the many testimonials we received on the completed UAT forms.
Agile Development Ramblings: Part II
The Process
In this project I was an Architect / Developer. The rest of the development team comprised a developer / SCRUM “Master” (see below), a Project Manager, a Business Analyst, a Data Architect, and an Agile Process Consultant. As with all projects, we reported into a Programme Manager. This was the first agile project for this customer. Consequently, we were proving the process as well as the product.
The Agile methodology we used was a mixture of SCRUM and DSDM. DSDM is an iterative methodology based on the core concepts of time boxed, prioritised development.
Elements of SCRUM were used to augment the internal iteration process and structure our day to day existence: Progress was followed using a “Burn Down Chart”, “Product -” and “Sprint - Backlogs” were created, (although these used the DSDM MoSCoW methodology) – See below for more detail on all these elements.
Notes on SCRUM
All the work to be done on a SCRUM project is recorded in the “Product Backlog”. This is a list of all the desired features for the final product. At the end of each Sprint a “Sprint Review Meeting” (see below) is held during which the Ambassador Users – in our case representatives of each of the organisations which will use our system - prioritise the remaining items on this Backlog. (see below for more detail).
This prioritised feature list is then taken by the Development Team who select the features they will target to complete in the next Sprint. These features are then moved from the Product Backlog to the “Sprint Backlog”.
2 Week Sprints
In SCRUM, iterations are called “Sprints”. Ours were 2 weeks long. (The length can be varied but it is recommended that they stay the same length throughout the project.) This worked well for us in a number of ways: they were regular, so the AU's could predict when they had to travel to London, they were long enough that a real chunk of functionality could be developed and then demoed, but short enough that everything done in development had to be relevant. They meant we stayed very focused throughout the 14 weeks.
The Sprint Plan, Estimation, and the Burn Down Chart
During the Sprint the team stays on track by holding brief daily meetings. The first meeting after the Sprint Planning Meeting is slightly different. Here, the team works down the Ambassador User prioritised feature list, breaking each feature down into manageable and unitary tasks. Each of these tasks is then entered into the Sprint Plan “Sprint Backlog” sheet as an individual item (see below). In addition, meetings, demos and any other requirements on team member’s time are added. It is important that all time spent during the project is tracked on the Sprint Plan.
The Sprint plan is a very simple, yet highly effective thing. It's an excel spreadsheet. The “Sprint Backlog” page is where all the action happens. Firstly the start and end of the Sprint are entered. This is used to calculate the time available. Each member of the development team (including project managers and business analysts) then enters their details in the top right hand corner. These details include their initials (used later in task allocation), their predicted availability for the project (e.g. a full-time developer is usually 90%), and any unavailable hours (i.e. holidays) are recorded as a negative number and deducted from the total available time. This information is then used to calculate the time each member has available to contribute to the project that Sprint (the “Avail” row).
The first allocation and estimation of each task then takes place. The team as a whole works through each of the entered task items in turn. For each, an “Owner” is allocated. They then estimate the time in hours they feel it will take them to complete the task.
The final step before the initial Sprint Planning is complete is to check that no team member is allocated more hours of work than they are capable of completing. This can be seen by comparing the “Avail” and “Alloc” rows for each member. If there is am imbalance in allocations, tasks can be re allocated. If reallocation is impossible then task items for the overworked member can be taken out of scope.
Finally, the effect of all this information can be seen simply and graphically by looking at the Burn Down Chart (“Sprint Chart”) which plots total estimated work remaining versus the time left in the Sprint. In a glance this lets everyone see the current estimated time versus the available time. Both these variables has a line. If your “estimated time” line is below the “available time” line then you're very happy. Too far below, and more tasks (and therefore features) can be brought into scope so everyone is well utilised. In the nightmare scenario where you're estimating above the “available time” line you know you (estimate) you have more work than there is time to do it. In this case you generally give things a few days to see if you can catch up with the line. If this fails, the team needs to discuss and take task items out of scope.
(Re)Estimation
Due to the simplicity and speed of the estimation process once the information is first entered, it is then possible to repeat this task every day – first thing in the morning is best. Each task that is not completed or is in scope has it's time to complete re-estimated. If a task has been completed since the last meeting, the estimate is set at “0”. As before, individual workloads can be checked and reallocation and de / re scoping used to ensure all workloads are manageable. As with the first session, the meeting ends with a look at the Sprint Chart and it's time lines.
This construction and updating of the Sprint Plan, especially the viewing of “the line” had the very pronounced effect of fostering a shared sense of responsibility in the team for everything everyone is doing. It was also very visible. Discussions which might have before happened in hidden Project Manager cabals are out in the open, and can be discussed by all. The whole team could not avoid the fact that things need to react to the current state of progress. This all resulted in a group who were all very focused on delivery. Not only that, but everyone was aware of what has to be delivered and what the workloads were like to reach that point. Everyone was responsible for the Sprint's success.
Is the fact that everyone has to attend a meeting a problem in itself? I'd say no. Things were always quick and relevant. Again the Sprint Plan ensured that. They were also quick. Fifteen minutes was usually all it took. Any time longer was when something of great importance to all has to be discussed.
Sprint Review Meetings
At the end of each Sprint the team demonstrated to the assembled AU’s the completed functionality of the real system, and outstanding and new features were discussed and prioritised (see below). We did this by showing the current system in all it's glory. It was my fear going into the first of these meetings that there would be nothing to show. I was wrong. What little we had done was ecstatically received. We had started to build what had been asked for, no matter how little we had actually achieved.
What's more, in the process of doing this we (the developers) had to explain our system. We asked questions to clarify our understanding in areas (which were many to begin with) of the business domain. We even got a user up to show us how they would do things on our fledgling system in their job.
It is worth noting that when I and the other developer joined the project, things had been running for a while. The Ambassador Users had been enlisted months before and had been along to a few meetings where the process had been explained to them and they had discussed and initially prioritised the planned high level features. Feedback gathered at the end showed this had left them confused and de motivated. Even when we did join the project, we did not to meet them for three weeks. These were spent setting up our development environments (1 week) and developing the first iteration (2 weeks). It transpired that show and tell was by far the best way to engage them and keep them interested.
However, over time, all the project team developed a relationship and shared sense of responsibility with the AU's. They felt engaged, and we gained an understanding of who they were and how they wanted to use the new system. This was particularly useful in our situation as we had such a diverse user base, drawn from seven different organisations, each of whom needed to use the system in a different way. In addition, we couldn't obfuscate and hide behind excuses and jargon because they were sitting in front of us. Similarly they had to think about what they wanted and if we gave them something that they asked for and it turned out that they had explained it badly, they realised the benefit of carefully thinking things through when making requests.
Feature Prioritisation with MoSCoW
“MoSCoW” is a way of prioritizing features. In the context of DSDM the MoSCoW technique is used to prioritize requirements. It is an acronym that stands for:
These criteria were used by the Ambassador Users to prioritise the outstanding elements on the Product Backlog at the end of each Sprint Planning Session. This then informed the features which we the developers picked off for development in each Sprint.
The approach benefits from being simple. Everyone could use it and more importantly could remember the terminology. They also were aware of the ramifications of allocating the different levels of priority to their requirements. Not everything asked for was developed.
The Process
In this project I was an Architect / Developer. The rest of the development team comprised a developer / SCRUM “Master” (see below), a Project Manager, a Business Analyst, a Data Architect, and an Agile Process Consultant. As with all projects, we reported into a Programme Manager. This was the first agile project for this customer. Consequently, we were proving the process as well as the product.
The Agile methodology we used was a mixture of SCRUM and DSDM. DSDM is an iterative methodology based on the core concepts of time boxed, prioritised development.
Elements of SCRUM were used to augment the internal iteration process and structure our day to day existence: Progress was followed using a “Burn Down Chart”, “Product -” and “Sprint - Backlogs” were created, (although these used the DSDM MoSCoW methodology) – See below for more detail on all these elements.
Notes on SCRUM
All the work to be done on a SCRUM project is recorded in the “Product Backlog”. This is a list of all the desired features for the final product. At the end of each Sprint a “Sprint Review Meeting” (see below) is held during which the Ambassador Users – in our case representatives of each of the organisations which will use our system - prioritise the remaining items on this Backlog. (see below for more detail).
This prioritised feature list is then taken by the Development Team who select the features they will target to complete in the next Sprint. These features are then moved from the Product Backlog to the “Sprint Backlog”.
2 Week Sprints
In SCRUM, iterations are called “Sprints”. Ours were 2 weeks long. (The length can be varied but it is recommended that they stay the same length throughout the project.) This worked well for us in a number of ways: they were regular, so the AU's could predict when they had to travel to London, they were long enough that a real chunk of functionality could be developed and then demoed, but short enough that everything done in development had to be relevant. They meant we stayed very focused throughout the 14 weeks.
The Sprint Plan, Estimation, and the Burn Down Chart
During the Sprint the team stays on track by holding brief daily meetings. The first meeting after the Sprint Planning Meeting is slightly different. Here, the team works down the Ambassador User prioritised feature list, breaking each feature down into manageable and unitary tasks. Each of these tasks is then entered into the Sprint Plan “Sprint Backlog” sheet as an individual item (see below). In addition, meetings, demos and any other requirements on team member’s time are added. It is important that all time spent during the project is tracked on the Sprint Plan.
The Sprint plan is a very simple, yet highly effective thing. It's an excel spreadsheet. The “Sprint Backlog” page is where all the action happens. Firstly the start and end of the Sprint are entered. This is used to calculate the time available. Each member of the development team (including project managers and business analysts) then enters their details in the top right hand corner. These details include their initials (used later in task allocation), their predicted availability for the project (e.g. a full-time developer is usually 90%), and any unavailable hours (i.e. holidays) are recorded as a negative number and deducted from the total available time. This information is then used to calculate the time each member has available to contribute to the project that Sprint (the “Avail” row).
The first allocation and estimation of each task then takes place. The team as a whole works through each of the entered task items in turn. For each, an “Owner” is allocated. They then estimate the time in hours they feel it will take them to complete the task.
The final step before the initial Sprint Planning is complete is to check that no team member is allocated more hours of work than they are capable of completing. This can be seen by comparing the “Avail” and “Alloc” rows for each member. If there is am imbalance in allocations, tasks can be re allocated. If reallocation is impossible then task items for the overworked member can be taken out of scope.
Finally, the effect of all this information can be seen simply and graphically by looking at the Burn Down Chart (“Sprint Chart”) which plots total estimated work remaining versus the time left in the Sprint. In a glance this lets everyone see the current estimated time versus the available time. Both these variables has a line. If your “estimated time” line is below the “available time” line then you're very happy. Too far below, and more tasks (and therefore features) can be brought into scope so everyone is well utilised. In the nightmare scenario where you're estimating above the “available time” line you know you (estimate) you have more work than there is time to do it. In this case you generally give things a few days to see if you can catch up with the line. If this fails, the team needs to discuss and take task items out of scope.
(Re)Estimation
Due to the simplicity and speed of the estimation process once the information is first entered, it is then possible to repeat this task every day – first thing in the morning is best. Each task that is not completed or is in scope has it's time to complete re-estimated. If a task has been completed since the last meeting, the estimate is set at “0”. As before, individual workloads can be checked and reallocation and de / re scoping used to ensure all workloads are manageable. As with the first session, the meeting ends with a look at the Sprint Chart and it's time lines.
This construction and updating of the Sprint Plan, especially the viewing of “the line” had the very pronounced effect of fostering a shared sense of responsibility in the team for everything everyone is doing. It was also very visible. Discussions which might have before happened in hidden Project Manager cabals are out in the open, and can be discussed by all. The whole team could not avoid the fact that things need to react to the current state of progress. This all resulted in a group who were all very focused on delivery. Not only that, but everyone was aware of what has to be delivered and what the workloads were like to reach that point. Everyone was responsible for the Sprint's success.
Is the fact that everyone has to attend a meeting a problem in itself? I'd say no. Things were always quick and relevant. Again the Sprint Plan ensured that. They were also quick. Fifteen minutes was usually all it took. Any time longer was when something of great importance to all has to be discussed.
Sprint Review Meetings
At the end of each Sprint the team demonstrated to the assembled AU’s the completed functionality of the real system, and outstanding and new features were discussed and prioritised (see below). We did this by showing the current system in all it's glory. It was my fear going into the first of these meetings that there would be nothing to show. I was wrong. What little we had done was ecstatically received. We had started to build what had been asked for, no matter how little we had actually achieved.
What's more, in the process of doing this we (the developers) had to explain our system. We asked questions to clarify our understanding in areas (which were many to begin with) of the business domain. We even got a user up to show us how they would do things on our fledgling system in their job.
It is worth noting that when I and the other developer joined the project, things had been running for a while. The Ambassador Users had been enlisted months before and had been along to a few meetings where the process had been explained to them and they had discussed and initially prioritised the planned high level features. Feedback gathered at the end showed this had left them confused and de motivated. Even when we did join the project, we did not to meet them for three weeks. These were spent setting up our development environments (1 week) and developing the first iteration (2 weeks). It transpired that show and tell was by far the best way to engage them and keep them interested.
However, over time, all the project team developed a relationship and shared sense of responsibility with the AU's. They felt engaged, and we gained an understanding of who they were and how they wanted to use the new system. This was particularly useful in our situation as we had such a diverse user base, drawn from seven different organisations, each of whom needed to use the system in a different way. In addition, we couldn't obfuscate and hide behind excuses and jargon because they were sitting in front of us. Similarly they had to think about what they wanted and if we gave them something that they asked for and it turned out that they had explained it badly, they realised the benefit of carefully thinking things through when making requests.
Feature Prioritisation with MoSCoW
“MoSCoW” is a way of prioritizing features. In the context of DSDM the MoSCoW technique is used to prioritize requirements. It is an acronym that stands for:
- MUST have this requirement to meet the business needs.
- SHOULD have this requirement if at all possible, but the project success does not reply on this.
- COULD have this requirement if it does not affect the fitness of business needs of the project.
- WOULD have this requirement at later date if there is some time left (or in the future development of the system).
These criteria were used by the Ambassador Users to prioritise the outstanding elements on the Product Backlog at the end of each Sprint Planning Session. This then informed the features which we the developers picked off for development in each Sprint.
The approach benefits from being simple. Everyone could use it and more importantly could remember the terminology. They also were aware of the ramifications of allocating the different levels of priority to their requirements. Not everything asked for was developed.
Agile Development Ramblings: Part I
Introduction
I've just completed my first Agile development project. We developed a fully functional prototype Java Portlet app in 14 weeks. We finished on budget, ahead of schedule and delivered all the initial requirements plus extras.
In addition, our Ambassador Users gave us the following feedback:
This is the first development project I've worked on which has been anywhere near as successful. I would completely attribute this to the Agile approach which was used. At the outset, my boss asked me to keep a note of how things went so I could share it with the team. This is the result.
Introduction
I've just completed my first Agile development project. We developed a fully functional prototype Java Portlet app in 14 weeks. We finished on budget, ahead of schedule and delivered all the initial requirements plus extras.
In addition, our Ambassador Users gave us the following feedback:
- “It is difficult to say how we could improve the process”.
- “I’ve been away for a few weeks and so much has happened”
- "The meetings I attended have been interesting and informative. The IT people seem to be bending over backwards to try and supply us with our needs and wants.”
- “I feel quite excited about how useful the portal will be when the programme is implemented. I know it's difficult to say but I really do think from what I've seen that Probation staff's job will be much assisted by the new system and feel that the time saved by using the portal is going to be phenomenal”
- "I have found the whole User Ambassador process to be an extremely interesting, enjoyable and enlightening experience."
- "I've recommended to my Organisation that we work this way in the future."
- “Our input is being used in shaping the Portal through the content and its usability resulting in a system in which all users will see the end product as a valuable resource”
- "I feel a great sense of achievement in what we have produced in such a short period of time.”
This is the first development project I've worked on which has been anywhere near as successful. I would completely attribute this to the Agile approach which was used. At the outset, my boss asked me to keep a note of how things went so I could share it with the team. This is the result.
Wednesday, May 31, 2006
Attempting to get on the JSR 286 (Portlet Spec) Expert Group: Part 1
After a fair bit of work at the coal face, I've decided to try and head off some of my personal nightmares at the pass. I've sent the following mail to JSR 286:
Dear Sir / Madam,
I am writing to request information on how to join the JSR 168 Expert Group.
I am an Agile Developer / Architect working for one of the worlds most respected Consultancies, as well as a JCP individual member of the last 4 years. I am also both a Sun certified J2EE Architect and Java 5 programmer.
I have extensive and recent experience of JSR 168 Portlet development (most recently with Websphere Portal Server 5.0.1) as well as the more established web and enterprise API’s (Servlet / JSP / JEE / EJB), frameworks (e.g. Struts and JSF) within, and external to the Portal model. In addition, I used to be a member of the Sun Microsystems Software Practice in the UK and consulted on some of the most important Sun Portal Server deployments of recent years.
What interests me most is the consideration of a open and standardised method of inter-portlet communication - an area which I understand this specification intends to address. I have “in the field” experience with IBM’s click to action and “wires” technology. In addition, I have experience of the WSRP specification. As an employee of a consultancy / systems integrator I believe I have a valuable role to play in representing consumers of the specification, both developers who use it, and also users who want their portals to be capable of richer, platform-independent functionality. As an ex employee of a vendor, I can also appreciate that the specification is not only suited for a single audience. I can help achieve this balance.
I am keen to participate as fully as possible and have no qualms about putting in whatever work will be required to fulfil my role as a contributor to this important specification.
I hope you feel as enthusiastic as I do and look forward to progressing this further. I hope I haven’t missed the boat to be a member of this exciting team.
Kind Regards,
Andrew
Fingers crossed...
After a fair bit of work at the coal face, I've decided to try and head off some of my personal nightmares at the pass. I've sent the following mail to JSR 286:
Dear Sir / Madam,
I am writing to request information on how to join the JSR 168 Expert Group.
I am an Agile Developer / Architect working for one of the worlds most respected Consultancies, as well as a JCP individual member of the last 4 years. I am also both a Sun certified J2EE Architect and Java 5 programmer.
I have extensive and recent experience of JSR 168 Portlet development (most recently with Websphere Portal Server 5.0.1) as well as the more established web and enterprise API’s (Servlet / JSP / JEE / EJB), frameworks (e.g. Struts and JSF) within, and external to the Portal model. In addition, I used to be a member of the Sun Microsystems Software Practice in the UK and consulted on some of the most important Sun Portal Server deployments of recent years.
What interests me most is the consideration of a open and standardised method of inter-portlet communication - an area which I understand this specification intends to address. I have “in the field” experience with IBM’s click to action and “wires” technology. In addition, I have experience of the WSRP specification. As an employee of a consultancy / systems integrator I believe I have a valuable role to play in representing consumers of the specification, both developers who use it, and also users who want their portals to be capable of richer, platform-independent functionality. As an ex employee of a vendor, I can also appreciate that the specification is not only suited for a single audience. I can help achieve this balance.
I am keen to participate as fully as possible and have no qualms about putting in whatever work will be required to fulfil my role as a contributor to this important specification.
I hope you feel as enthusiastic as I do and look forward to progressing this further. I hope I haven’t missed the boat to be a member of this exciting team.
Kind Regards,
Andrew
Fingers crossed...
Subscribe to:
Posts (Atom)



{kind=link}